|
Key SQL Performance Situations to Watch Out For - Part Three of Three
View Part One - SQL Server Blocking
View Part Two - SQL Server Expressions
Have you ever opened up a really big book lately? Let’s say someone handed you a copy of War and Peace by Tolstoy and told you that there was an interesting phrase found on page 435. How would you go about looking up that page? Would you start at the beginning of the book, turning page after page, one at a time looking for page 435? Would you start at the back of the book and do the same? The most common answer to that is “Who’s Tolstoy?” but following at a close second place is “No way? What are you… stupid or something? Why would anyone do that?” The most common way people would go about finding that page number would be to start in the middle.
Sure. You’d start in the middle, and then you’d divide the search of the book in half estimating the approximate location of the page. Then comparing the page number you’re looking at to the desired one, you’d know whether to look in the right half of the book or the left half. You’d repeat this process with tighter and tighter division and with smaller and smaller number of pages until you find the page you are looking for.
Why do we do it this way? We search books this way, simply because our human experience has taught us that this is the most efficient way to find pages we are looking for. So what does this have to do with query performance?
When figuring out how best to access data within SQL Server, the query optimizer takes the query that you submit to it and performs some analysis of the objects involved. It tries to determine what indexes (just like the numbering of pages in a book) are available and if they are useful or not to your query, it tries to determine if the criteria in the where clause of the query allows it to use any of the indexes in an efficient manner. When there is no other efficient way to access data within the tables involved in the query, the query processor will process all of the rows in the table one at a time to give you the results.
This is referred to as a Full Table Scan. This is the equivalent of having a book that doesn’t have any page numbers, but being told that somewhere in the book is some piece of information that you need to know. So, the only way to access this information is to look at every page one at a time searching for the information you need. Sound like fun? In a 10 page Children’s book, this might be fine, but in War and Peace by Tolstoy, not so much.
Having an index on a table tied to columns that are searchable (Names of things, IDs, Foreign Keys, etc.) allows the query optimizer more options when a query is being processed. It can look at the Where clause and joins of the query to determine which indexes would best access the data and then perform searches on the data very similarly to how we would access a particular page within a book, which can dramatically improve the performance of accessing the data.
To show how this looks within a query plan, the following 3 illustrations of query plans show 3 different types of scans: Index Scans, Clustered Index Scans, and Table Scans.

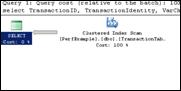

Full Table Scans also are not scalable as the data grows. It’s very simple. As more data is added to a table, full table scans must process more data to complete and therefore they will take longer. Also, they will produce more Disk and Memory requests, further putting strain on your equipment.
Consider a 1,000,000 row table that a full table scan is performed on. SQL Server reads data in the form of an 8K data page. Although the amount of data stored within each page can vary, let’s assume that on average 50 rows of data fit in each of these 8K pages for our example. In order to perform a full scan of the data to read every row, 20,000 disk reads (1,000,000 rows / 50 rows per page). That would equate to 156MB of data that has to be processed, just for this one query. Unless you have a really super fast disk subsystem, it might take it a while to retrieve all of that data and process it. Now then, let’s say assume that this table doubles in size each year. Next year, the same query must read 312MB of data just to complete.
If a unique index is used instead to find the row needed, a rule of thumb is to assume that about 1 log2(N) disk reads at most need to be performed to find the data. In the formula, N = Number of rows to process, and log2 means logarithm for base 2 or binary logarithm. So, let’s assume that we still have our 1,000,000 rows in our table. Using our rule of thumb formula (which isn’t necessarily accurate but will give you an idea of how much more efficient these are) we find that 1 log2(1,000,000 rows) = 7 disk reads. So, to find the one row you need in this scenario, only 7 disk reads need to be performed, which is much different than 20,000.
Assuming our 8K pages and assuming it has to read all 7 different pages, we find that running this query yields only 56K of data that needs to be processed. Looking at our projected growth in a year, where the table now has 2,000,000 rows of data in it, we can apply our same rule of thumb algorithm and we find that 1 log2(2,000,000 rows) = 7 disk reads. So, doubling the rows in this case doesn’t impact how many reads we have to do to find the data! Let’s look at 10,000,000 rows. Using our same algorithm, we find that 1 log2(10,000,000 rows) = 8 disk reads. In our example, processing this much data by using a scan would yield 200,000 disk reads instead of 8. So, we see that modifying our queries to use indexes for large, ever growing datasets, is far more scalable and efficient as the data grows than allowing full table scans.
There have been cases where applications perform fine under small load, but will absolutely crash a system when even mild increase in load is put upon them. If a SQL Server doesn’t appear to scale well when the load increases, chances are you need to analyze the running queries to determine if they are scanning rather than performing seeks.
View previous article on Performance Situations to Watch Out for - SQL Server Blocking.
View previous article on Performance Situations to Watch Out for - SQL Server Expressions.
|