|
Key SQL Performance Situations to Watch Out For - Part Two of Three
View Part One - SQL Server Blocking
View Part Three - Full Table Scans
Expression = Expression
a2 b2 = c2. Anyone remember what this is? Pythagorean Theorem anyone? It clearly states that in any right triangle, the square on the hypotenuse is equal to the sum of the squares on the other two sides. So what? What does it have to do with SQL Server or performance? Look closely at the formula. Let’s consider the letter “c” in the equation as a column in a table used in a where clause of a select statement. There is a component on the left side of the equal sign that requires calculation. There is also a component on the right side of the equal sign that also requires a calculation. What does this mean to performance in SQL Server?
When SQL Server has to perform calculations on both sides of a comparison operator within a Where clause, then this criteria cannot be considered when evaluating the usage of indexes. SQL Server must try to use other criteria within the query to figure out which indexes to use, and if there are none, the query processor will scan all of the rows in the table, evaluating these expressions one row at a time, in order to determine which rows to process or return.
Let’s consider the following change to the Pythagorean Theorem formula.
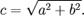
Notice that by using some simple algebra to solve for c, now we have a different scenario. On the left side of the equal sign we now have a column with no calculations performed on it, while on the right side we have an expression. The query optimizer can now consider indexes that include the “c” column, since it can evaluate the expression at compile time and not at run-time.
Here are some examples of poorly performing SQL statements that research shows to occur a great deal in applications.
SELECT A.*
FROM Customer as A
WHERE A.City ', ' A.State = @SearchField ;
SELECT A.*
FROM Customer as A
WHERE A.FirstName ' ' A.LastName = @SearchField ;
SELECT A.*
FROM OrderDetail as A
INNER JOIN Product As B on (A.ProductID = B.ProductID)
WHERE (A.Qty * B.ItemPrice) >= 100.00 ;
In two of the three example queries, the SQL could be adjusted to solve for a column on one side of the comparison and have the potential to be evaluated by indexes if they are available. There are expressions on both sides of the comparison, however, so these will perform full scans of the tables involved to find the criteria in question.
Here are examples of changes that could be made to these queries to allow them to work more optimally, should indexes be present on the columns involved.
SELECT A.*
FROM Customer as A
WHERE A.City = @SearchFieldCity
AND A.State = @SearchFieldState ;
SELECT A.*
FROM Customer as A
WHERE A.FirstName = @SearchFieldFirstName
AND A.LastName = @SearchFieldLastName ;
Why isn’t the third query able to be optimized in this way? In the first two examples, the expression on the right of the comparison operator can be resolved at compile time. With the third query, no matter how you manipulate the formula, there will be elements on both sides of the comparison operator that cannot be known until the query is executed. Consider the following two examples of variations of the third query.
SELECT A.*
FROM OrderDetail as A
INNER JOIN Product As B on (A.ProductID = B.ProductID)
WHERE A.Qty >= 100.00 / B.ItemPrice ;
SELECT A.*
FROM OrderDetail as A
INNER JOIN Product As B on (A.ProductID = B.ProductID)
WHERE B.ItemPrice >= 100.00 / A.Qty ;
As you can see, no matter how it is manipulated, there is a column on both sides of the equation and one of them must be involved with the calculation.
Here is another example that includes the query plan of each case.
SELECT COUNT(*)
FROM dbo.TransactionTable1 AS A
WHERE A.IntFlag 1 = 3;
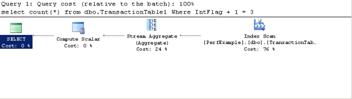
Notice how the first thing that happens (you read these from right to left) is an Index Scan. This is looping through an index, but it has to look at every node of the index to process the data for the query because of the way the WHERE clause is written with an Expression = Expression. On the test machine, with the test example database, this yielded a cost of 2.78. However, by making the subtle change below, the cost was reduced to 0.0032 on the same machine in the same database.
SELECT COUNT(*)
FROM dbo.TransactionTable1 AS A
WHERE A.IntFlag = 3 – 1;

Notice how the first thing this query does (again, read from right to left) is an Index Seek. This means that it can actually use the index as intended instead of having to scan through all of the data. Also take note that the next activity processed by the query, Stream Aggregate, is drastically reduced in cost between the first query and the second query. This is very common. The estimated cost for the other activities of the query will go down when altering queries to quit scanning because the query optimizer tries to guess at how many rows will be processed by each step. When an index is used, the query optimizer can use statistics about the data in the index to more accurately guess at how many rows will be processed. There are cases however, as in the case of Filter tasks, or Bookmark Lookup tasks where the actual physical time will be saved performing these steps when and index is used. This is because these types of activities must actually be performed for each row that is returned by the data gathering steps (Scans and Seeks) and therefore the performance of the query overall would be improved if they didn’t have to perform their activities on every row and instead only have to perform them on the necessary rows found by the Seek.
So what does all of this mean? To summarize, the goal is to avoid the processing of every single row of a table when returning rows is a desirable thing. However, having expressions on both sides of the comparison operator can cause this very thing to happen. To optimize these situations, look for areas where simple algebra can be used to solve for one of the columns or where multiple parameters can be used instead of comparing a value to a calculation of columns.
View previous article on Performance Situations to Watch Out for - SQL Server Blocking.
View next article on Performance Situations to Watch Out for - SQL Server Expressions.
|